


III. Quelques (petits) rappels▲
III-A. Terminologie▲
Si l'emploi des mots « temps réel » , « tâche »… vous rappelle des lointains souvenirs avec une salle de classe comme décor, ce paragraphe est pour vous ! Les pros passeront directement au suivant.
Appel système (system call) : depuis une application utilisateur, lorsque l'on appelle un service fourni par le noyau, on fait alors un appel système. Cet appel système bascule l'application en mode noyau. Sous Linux, le noyau propose entre 300 et 400 services, ce nombre dépend de l'architecture utilisée. Si vous avez un peu de temps, vous pouvez jeter un œil dans les sources du noyau Linux, la liste se trouve dans le fichier entry.S correspondant à votre architecture matérielle. Xenomai en propose une dizaine.
Dans la pratique, tout ceci est transparent pour le développeur puisque les appels se font à travers des bibliothèques « système », donc on ne voit jamais réellement les appels aux fonctions du noyau. Pour la fonction getpid par exemple, la bibliothèque système l'implémentant est la glibc; à l'intérieur de celle-ci se trouve un appel au service n° 20, sys_getpid, du noyau Linux(1).
En mode noyau, toutes les structures internes (tâches, structures abstraites derrière les descripteurs, registres matériels...) sont alors accessibles et donc modifiables.
Affinity (ou CPU binding) : restriction de l'exécution d'une tâche sur un ou plusieurs CPU. Cette affectation permet évidemment de dédier une ressource processeur, mais elle optimise également l'accès à la mémoire cache.
Jiffy : intervalle entre deux ticks d'horloge.
LKM : Linux Kernel Module, module du noyau Linux, chargeable et déchargeable dynamiquement. Ce code, généralement un driver matériel, est exécuté en mode noyau.
Mainline : version stable d'un logiciel, par opposition aux versions de développement.
Noyau Linux (kernel) : il remplit plusieurs tâches : l'ordonnancement des processus, la fourniture d'appels système aux applications utilisateur, la gestion des entrées/sorties matérielles.
Inutile d'approfondir plus cette description car le howto du noyau Linux, Wikipedia ou encore Understanding the Linux Kernel(2), pour ne citer qu'eux, vous apporteront des explications très détaillées.
Points de préemption, de descheduling : appels au scheduler afin qu'il élise éventuellement une autre tâche.
Quantum, timequantum, timeslice, slice : dans un ordonnancement coopératif ou préemptif avec round-robin, temps pendant lequel une tâche profitera du processeur.
Round-robin : lorsque deux tâches ont la même priorité, ce mécanisme donne alternativement la main à l'une et à l'autre. De manière plus générale, dans un système préemptif, si n tâches ont la même priorité, deux politiques sont possibles : soit la tâche élue s'exécute et passe la main à la suivante lorsqu'elle se termine, et ainsi de suite ; soit les tâches s'exécutent à tour de rôle chacune pendant un quantum de temps défini. D'un point de vue utilisateur, cette dernière solution a pour effet de « lisser » l'exécution des applications.
RTOS : Real Time Operating System, OS temps réel.
Vanilla kernel : noyau Linux « officiel » dont les sources se trouvent sur www.kernel.org, par opposition aux noyaux modifiés par les éditeurs (Redhat, Mandriva...).
III-B. Les processus et les threads▲
Quelle différence y a-t-il entre un processus et un thread sous Linux ?
Si vous posez la question à un développeur, il vous répondra probablement que cela n'a rien à voir en vous expliquant qu'un processus peut comporter plusieurs threads, que l'espace d'adressage mémoire est commun... et bien d'autres arguments tout à fait justes.
Si vous reposez la même question à l'architecte d'une application temps réel, il vous répondra qu'il n'y a pas de différence fondamentale car les deux sont traités de la même manière dans le scheduler. C'est le point de vue qui est également adopté dans ce document. Dans un contexte d'ordonnancement et de priorité, les termes tâche, processus et thread se confondent.
III-C. La latence▲
Le principal problème pour qu'un OS satisfasse à une utilisation temps réel est la latence. La latence est le délai entre le moment où un traitement est nécessaire et l'instant où il est effectif, c'est par exemple le temps qui sépare la génération d'une interruption de son traitement.
Dans un système temps réel, la latence est bornée afin de garantir le déterminisme temporel.
La valeur de latence retenue pour décrire un système d'exploitation temps réel représente toujours le cas le plus défavorable.
Plus la latence est faible, plus on considère le système comme étant performant.
Dans un OS temps réel, la latence est classiquement de l'ordre de quelques microsecondes.
III-D. La préemption▲
(3) Le remplacement involontaire du processus s'exécutant par un autre est appelé préemption. Le terme involontaire(4) signifie que le processus en cours ne s'est pas, par exemple, mis en sommeil ou en attente de réception de données.
III-E. Les modes user et kernel▲
Lors de son exécution, un processus fait des allers-retours entre le mode utilisateur, dans lequel se déroulent les algorithmes codés par les développeurs, et le mode noyau pour les appels systèmes (lecture d'une socket, consultation de la date système, etc.).
Dans cet exemple, P1 et P2 ont la même priorité et s'exécutent en round-robin :
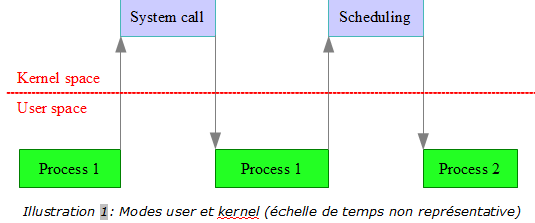
Le problème du noyau Linux est que, par défaut, il n'y a pas de préemption à l'intérieur du noyau.
Pour faire du temps réel, cela n'est pas tolérable pour au moins deux raisons :
un processus de basse priorité en mode noyau ne peut pas être interrompu par un processus de haute priorité, on se situe alors dans un cas d'inversion de priorité ; le temps passé à l'intérieur du noyau peut être très long.
Nous verrons par la suite qu'il est possible de préempter les tâches à l'intérieur du mode noyau.
III-F. L'accumulation des latences dans la gestion d'une interruption matérielle▲
Rentrons maintenant un peu plus dans le détail et analysons comment est traitée une interruption(5). Dans cet exemple, le matériel génère une interruption (signalant des données disponibles, l'expiration d'un timer, etc.) et un processus doit prendre en compte cet événement.
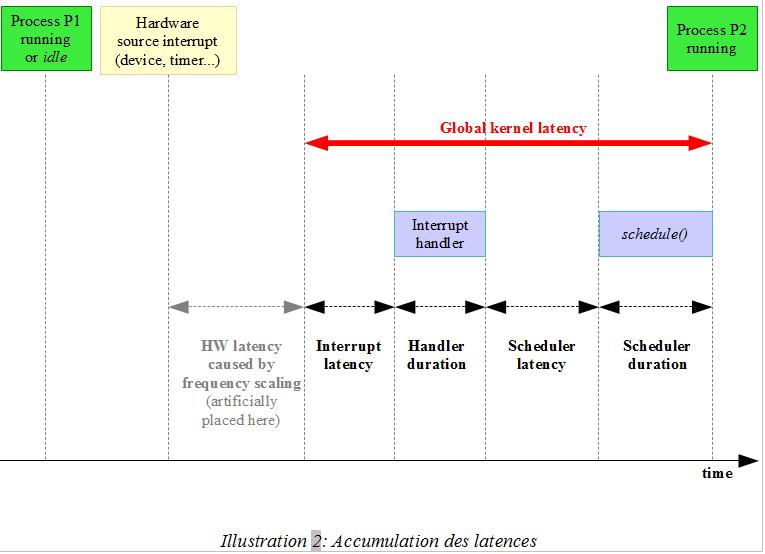
La latence de l'interruption(6) est le temps entre la génération de l'interruption et l'appel du handler.
Elle est augmentée par :
- le masquage des interruptions à l'intérieur du noyau : le traitement est alors reporté au démasquage ;
- le partage d'une ligne d'interruption : tous les handlers installés sur cette interruption sont alors appelés (charge à eux, ensuite, de gérer l'absence de « cause réelle »), ces appels multiples sont forcément coûteux ;
- l'arrivée d'une interruption plus prioritaire : matériellement, si deux interruptions arrivent simultanément, l'arbitrage est fait par le contrôleur d'interruptions (APIC).
Généralement, les handlers d'interruption ne sont pas réentrants. Par conséquent, afin de prévenir toute autre interruption qui serait alors imbriquée, la ligne est temporairement masquée. Pour fixer les idées, voici un extrait simplifié d'un driver de carte Ethernet (linux-2.6.25/drivers/net/e100.c) :
static irqreturn_t e100_intr(int irq, void *dev_id)
{
...
/* Au début du handler, on considère le cas où la ligne d'interruption est partagée, « est-ce pour nous ? »: telle est l'utilité de ce test */
if(stat_ack == stat_ack_not_ours || /* Not our interrupt */
stat_ack == stat_ack_not_present) /* Hardware is ejected */
return IRQ_NONE;
/* Acquittement de l'interruption */
iowrite8(stat_ack, &nic->csr->scb.stat_ack);
...
/* Traitement... */
if(...) {
...
__netif_rx_schedule(netdev, &nic->napi);
}
return IRQ_HANDLED;
}Si des interruptions sont masquées pendant l'exécution du handler, cela signifie que toutes celles arrivant vont être en attente (pending), augmentant ainsi leur latence... Mais rassurez-vous, ce mécanisme est optimisé : l'idée consiste à découper le handler en deux :
- une première partie -courte- qui va masquer les interruptions, acquitter la ligne, effectuer un nombre d'opérations minimum et surtout autoriser le déroulement d'une seconde partie, mais pas tout de suite ! En fait, ce sera seulement après avoir démasqué les interruptions. L'avantage ? Plutôt que de faire un long traitement atomique, la séparation permet aux interruptions en attente d'être traitées plus rapidement ;
- dans la seconde portion du handler, le traitement continue mais avec des contraintes de temps (un peu) plus relâchées.
Dans la terminologie Linux, « top half » est le « vrai » handler et « bottom half » (ou encore soft IRQ) est celui appelé dans un second temps.
Ce n'est pas encore tout à fait terminé, puisqu'il faut trouver un moment pour exécuter notre bottom half. L'introduire dans le scheduler comme une tâche ? Possible, mais par défaut, ce n'est pas la solution qui a été retenue. Les choses vont alors se compliquer (très) légèrement : le noyau Linux possède en fait un second scheduler dédié aux bottomhalf qui prennent alors le nom de tasklet(7). Ce scheduler de tasklets est prioritaire sur le scheduler de tâches(8).
On entre ensuite dans le scheduler en lui-même, il trouvera la prochaine tâche courante parmi les n éligibles puis basculera les contextes. Ce temps correspond à la durée de scheduling.
Un dernier point reste à aborder... Indiquée en gris sur le schéma, la latence induite par les économies d'énergie est matérielle. Elle est un peu particulière car elle n'est pas réellement ajoutée juste après la génération de l'interruption mais elle correspond à une moindre performance du processeur. Afin d'économiser de l'énergie, celui-ci diminue sa vitesse lorsqu'il n'a rien à faire et met un certain temps à retrouver ses pleines capacités.
III-G. Le noyau Linux et ses évolutions▲
Ce paragraphe détaille les mécanismes du noyau introduisant des temps de latence, et comment celle-ci a diminué au fil des évolutions.
Le problème de base est de rendre les processus en mode noyau préemptibles. Concrètement, cela signifie que si un processus P1 fait un appel système et que, un autre, P2 - plus prioritaire - devient éligible, P1 suspendra son exécution, P2 deviendra alors le processus courant et pourra faire à son tour des appels système.
Conclusion : le noyau doit être réentrant, et ce n'est pas forcément simple à appliquer sur un code déjà existant de plusieurs centaines de milliers de lignes... Le développement réentrant implique la mise en œuvre d'exclusion mutuelle dès qu'une donnée est partagée.
L'idéal pour résoudre un problème étant de le partager avec d'autres, la réentrance du noyau fît son apparition avec le support multiprocesseur (SMP), rien à voir avec le temps réel donc.
Ne confondez pas la préemption et la réentrance.
La réentrance est nécessaire pour la préemption. Cependant, un noyau peut être réentrant sans être préemptible, cela signifie simplement qu'il ne comporte alors pas de points de descheduling.
Dans la version 2.2, il existait un verrou appelé BKL (Big Kernel Lock) qui protégeait les sections critiques du noyau. La portée de ce « supersémaphore » était très étendue, en effet on trouvait des appels à lock_kernel() et à unlock_kernel(), à des emplacements très variés du code qui allaient des sémaphores IPC au driver de souris USB. Une grande partie des appels système étaient donc, dans les faits, sérialisés.
Un exemple dans drivers/usb/mousedev.c du kernel 2.2.26 :
static int mousedev_release(struct inode * inode, struct file * file)
{
struct mousedev_list *list = file->private_data;
struct mousedev_list **listptr;
lock_kernel();
...
unlock_kernel();
return 0;
}L'évolution de la 2.2 vers la 2.4 a supprimé la majorité des appels au BKL au profit de verrous beaucoup plus localisés.
Exemple comparatif : fs/open.c du noyau 2.2.6:
asmlinkage int sys_close(unsigned int fd)
{
int error;
struct file * filp;
lock_kernel();
...
unlock_kernel();
return error;
}Et celui du noyau 2.4.36, le verrou est local au système de fichiers :
asmlinkage long sys_close(unsigned int fd)
{
struct file * filp;
struct files_struct *files = current->files;
write_lock(&files->file_lock);
...
write_unlock(&files->file_lock);
return -EBADF;
}Ce n'est finalement qu'à partir de la version 2.6, que les choses commencent à devenir vraiment intéressantes... Les besoins multimédias étant passés par là, l'exécution d'applications temps réel « mou »(9) est possible grâce à la préemption en mode kernel, via l'ajout de points de descheduling dans les appels système. Comme nous le verrons par la suite, possible ne veut pas dire obligatoire car par défaut le noyau n'est toujours pas optimisé en latence(10).
Il faut cependant noter que cette préemption n'est que partielle puisqu'elle exclut les sections critiques et des handlers d'interruption. Parmi les améliorations importantes, on trouve également dans cette version un nouveau scheduler(11) qui choisit la tâche à exécuter parmi celles éligibles en un temps quasi constant, et ce, quel que soit le nombre de tâches(12).
III-H. Les mécanismes de synchronisation▲
Dans le noyau, il existe plusieurs implémentations des sections critiques. Le choix est guidé par les performances : temps d'exécution de la section (bref ou long), nombre et type d'accès (lecture ou écriture) à une variable partagée, donnée accessible par plusieurs CPU, etc.
Pour les nommer, on peut par exemple citer les spinlocks, les RCU, les sémaphores. Des explications détaillées sont disponibles à cette adresse :
http://linux-security.cn/ebooks/ulk3-html/0596005652/understandlk-CHP-5-SECT-2.html.
III-I. Comment gérer la priorité des processus ?▲
Lors du développement d'applications « classiques », cet aspect n'est que rarement abordé, d'où ce paragraphe de rappel.
La fonction sched_setscheduler() prend en paramètre la stratégie d'ordonnancement (policy). Vous vous demandez sûrement ce que vient faire cette stratégie alors que l'on parle de priorités. Explications.
Il y a quatre stratégies ou classes d'ordonnancement disponibles :
- SCHED_OTHER : la politique de temps partagé (time slicing) utilisée par défaut, la priorité statique associée est toujours 0. À l'intérieur de cette classe, on peut pénaliser ou gratifier un processus en modifiant son quantum de temps via la fonction nice(), c'est la priorité dynamique. Elle n'est pas abordée dans ce document, par priorité on sous-entendra toujours priorité statique ;
- SCHED_BATCH(13): basé sur SCHED_OTHER, sert aux processus longs et non interactifs (calculs par exemple). Un processus s'exécutant en SCHED_BATCH a un quantum plus long et fait donc moins de rescheduling ;
- SCHED_FIFO : pour les processus temps réel, les niveaux de priorité vont de 1 (la plus faible) à 99. Si un processus appliquant la politique SCHED_FIFO s'exécute, il ne peut être préempté que par un processus de priorité strictement supérieure. L'emploi du terme « temps réel » est un peu usurpé car les mécanismes de scheduling sont exactement les mêmes que pour les processus SCHED_OTHER, la seule chose qui change est la priorité ;
- SCHED_RR : basé sur SCHED_FIFO, avec l'utilisation du round-robin.
Afin de trouver le processus qui doit s'exécuter, l'ordonnanceur parcourt d'abord la liste des processus temps réel (SCHED_FIFO et SCHED_RR) et prend celui de plus haute priorité. Si cette liste est vide, il passe à la liste contenant les processus SCHED_OTHER et si elle également vide, il traite les processus SCHED_BATCH.
Par défaut, Linux possède 101 niveaux de priorité (14).
Il faut des privilèges superutilisateur pour migrer un processus vers les classes temps réel.
La compréhension de ces stratégies d'ordonnancement est importante car Xenomai les utilise sous l'intitulé secondary mode.
À noter qu'il existe également une fonction sched_setaffinity qui affecte un processus à un ou plusieurs CPU.
III-J. Comment gérer le temps ?▲
Du quantum aux timers de plusieurs secondes, comment Linux gère-t-il le temps ?
Commençons tout d'abord par répondre à deux questions basiques : qui a besoin du temps et quelles « horloges » utiliser ?
III-J-1. Le modèle « tout périodique »▲
À la première question, nous avons quatre bonnes réponses(15) :
- L'horloge interne (jiffies) du noyau qu'il faut incrémenter. Rien de très compliqué ici, lors de l'initialisation, on programme un timer pour appeler un handler d'interruption à une fréquence f. Chaque appel incrémentera la variable jiffies ;
- Le ou les processus s'exécutant afin de mesurer l'occupation CPU (accounting) ;
- Les processus en temps partagé : une fois expiré le quantum de temps alloué à un processus, le scheduler en élit un autre ;
- Les actions différées : « timers », time-out...
Avec cette organisation, la gestion du temps est relativement simple puisqu'une seule horloge est nécessaire. Il suffit d'une interruption matérielle périodique et le tour est joué : à chaque tick d'horloge on incrémente les jiffies, on vérifie s'il existe des timers expirés, etc.
L'autre question était avec quel composant le faire : ce sera le travail des timers programmables.
Vous vous demandez quelle fréquence positionner ? Trop lent et les timers seront imprécis. Trop rapide et l'overhead induit pénalisera le système. Ces interrogations sont tout à fait justifiées. On peut même rajouter une remarque empreinte d'écologie : les économies d'énergie passent par une diminution de la fréquence du processeur lorsque le système n'est pas chargé (idle), or cet état n'est pas atteignable si on est sans cesse réveillé par une horloge.
La latence matérielle augmente lorsque les fonctionnalités d'économie d'énergie sont activées.
III-J-2. Le modèle tickless▲
Cette dernière approche est très intéressante pour expliquer les dernières évolutions (2.6.25) du noyau. L'idée consiste à distinguer le système chargé (c'est-à-dire avec des processus éligibles) et idle.
Dans l'état idle, le comptage du temps consommé par le processus courant et le rafraîchissement du quantum n'existent pas. Quant à l'horloge interne, plutôt que la mettre périodiquement à jour, on la rafraîchit lorsque l'on en a besoin.
La liste des horloges disponibles se trouve dans le fichier /sys/devices/system/clocksource/clocksource0, par exemple sur un PC :
hpet acpi_pm jiffies tscQuant aux évènements différés, la solution passe par un timer programmé pour générer une interruption, ce mécanisme est alors nettement plus précis que le modèle « tout périodique ».
De ce modèle tickless découlent les timers haute précision (HRT Timers).
Les timers disponibles sont listés dans le fichier /proc/timer_list(16) :
...
Clock Event Device: hpet
...
Clock Event Device: lapic
...
Clock Event Device: lapic
...Si le système est en charge, le mécanisme périodique présenté au début assurera le comptage du temps CPU et le time slicing. Sa fréquence est par défaut de l'ordre de la centaine de Hertz.
À noter que les horloges grand public, quelle que soit leur précision « annoncée » dérivent dans le temps et en fonction de la température.
Pour connaître leur précision « réelle », il faut alors se reporter à la datasheet du composant.
III-K. Inversion et héritage de priorité▲
Considérons trois tâches :
- Thi de haute priorité ;
- Tmed de priorité moyenne ;
- Tlow de faible priorité.
Ainsi qu'une ressource partagée protégée par le sémaphore S.
Le but d'un scheduler préemptif est que la tâche la plus prioritaire soit celle qui s'exécute.
Imaginons le cas suivant :
Tlow s'exécute, prend S et accède à la ressource partagée.
Thi arrive parmi la liste des tâches éligibles et logiquement s'exécute. Cette tâche veut également accéder à la ressource, mais elle se retrouve bloquée par le sémaphore S.
Maintenant, c'est au tour de Tmed d'entrer dans la liste des tâches éligibles : Thi est en attente de S, Tlow est moins prioritaire, c'est donc Tmed qui s'exécute.
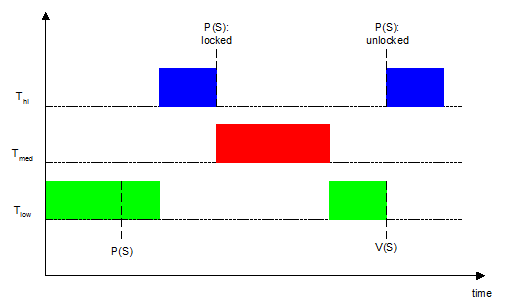
On se trouve alors dans un cas d'inversion de priorité car ce n'est pas la tâche Tmed qui devrait s'exécuter mais Thi.
Substituons ce cas d'école par un système où Tmed est remplacé par n tâches de priorités comprises entre celles de Tlow et Thi, il devient alors très lourd de calculer le moment où Thi s'exécutera…
L'idéal serait que Tmed laisse Tlow s'exécuter afin de libérer S le plus rapidement possible.
Cet idéal existe et est implémenté sous le nom d'« héritage de priorité ». Concrètement, lorsque Thi va demander le sémaphore possédé par Tlow, l'héritage de priorité va aligner la priorité de Tlow sur celle de Thi, le rendant ainsi ininterruptible par des tâches de moindre priorité. Lorsque Tlow relâchera le sémaphore, Thi s'exécutera alors immédiatement.
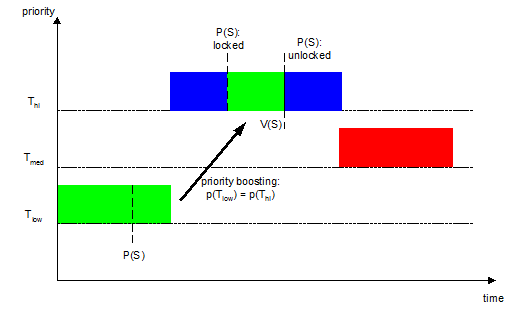
Xenomai utilise également le principe d'héritage de priorité.